SysNucleus WebHarvy 6.5.0.193 (x64)
Type PC Software Language English Total size 108.5 MB
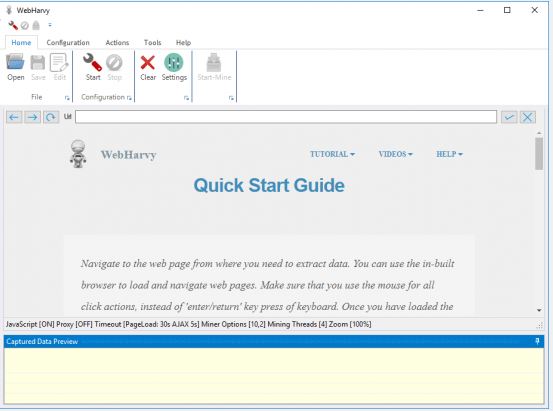
Intuitive Powerful Visual Web Scraper. WebHarvy can automatically scrape Text, Images, URLs & Emails from websites, and save the scraped content in various formats. WebHarvy is an application designed to help you scrape images, text or any data displayed on a web page using an advanced built-in browser and an easy point and click interface.
– Incredibly easy-to-use, start scraping within minutes
– Extract data from multiple pages/categories/keywords
– Save extracted data to file or database
– Built-in scheduler and proxy support
Point and Click Interface
WebHarvy is a visual web scraper. There is absolutely no need to write any scripts or code to scrape data. You will be using WebHarvy’s in-built browser to navigate web pages. You can select the data to be scraped with mouse clicks. It is that easy !
Scrape Data Patterns Auto Pattern Detection
WebHarvy automatically identifies patterns of data occurring in web pages. So if you need to scrape a list of items (name, address, email, price etc) from a web page, you need not do any additional configuration. If data repeats, WebHarvy will scrape it automatically.
Export scraped data Export data to file/database
You can save the data extracted from web pages in a variety of formats. The current version of WebHarvy Web Scraper allows you to export the scraped data as an XML, CSV, JSON or TSV file. You can also export the scraped data to an SQL database.
Scrape data from multiple pages Scrape from Multiple Pages
Often web pages display data such as product listings in multiple pages. WebHarvy can automatically crawl and extract data from multiple pages. Just point out the ‘link to the next page’ and WebHarvy Web Scraper will automatically scrape data from all pages.
Keyword based Scraping Keyword based Scraping
Scrape data by automatically submitting a list of input keywords to search forms. Any number of input keywords can be submitted to multiple input text fields to perform search. Data from search results for all combinations of input keywords can be extracted.
Scrape via proxy server Proxy Servers / VPN
To scrape anonymously and to prevent the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers or VPN. Either a single proxy server address or a list of proxy server addresses may be used.
Category Scraping Category Scraping
WebHarvy Web Scraper allows you to scrape data from a list of links which leads to similar pages/listings within a website. This allows you to scrape categories and sub-categories within websites using a single configuration.
Regular Expressions
WebHarvy allows you to apply Regular Expressions (RegEx) on Text or HTML source of web pages and scrape the matching portion. This powerful technique offers you more flexibility while scraping data.
Run JavaScript
Run your own JavaScript code in browser before extracting data. This can be used to interact with page elements or invoke JavaScript functions already implemented in target page.
Download Images
Images can be downloaded or image URLs can be extracted. WebHarvy can automatically extract multiple images displayed in product details pages of eCommerce websites.
Automate browser interaction
WebHarvy can be easily configured to perform tasks like Clicking Links, Selecting List/Drop-down Options, Input Text to a field, Scrolling page etc.
What’s New
Requires Windows
WebHarvy requires Windows operating system to run. If you want to run WebHarvy on your Mac you should either install Windows via BootCamp or run WebHarvy via Parallels. OS X / macOS is currently not supported.
Built on Chrome
The latest version of WebHarvy is built using Google’s open source Chrome browser project, which makes it more secure, stable and faster.
Run from cloud
WebHarvy can be run in an Amazon AWS EC2 Windows Instance.